![[NLP] Don’t Stop Pretraining: Adapt Language Models to Domains and Tasks 논문 리뷰(1)](https://img1.daumcdn.net/thumb/R750x0/?scode=mtistory2&fname=https%3A%2F%2Fblog.kakaocdn.net%2Fdn%2FUfg4J%2Fbtq5LLK13tG%2FFwmBXUDosTX9RMSz9v2Pa1%2Fimg.png)
1. Introduction
오늘날 pretrained 언어모델은 방대한 양의, 다양한 코퍼스에서 학습된다.
Ex) RoBERTA(BERT를 최적화한 모델)는 160GB의 텍스트로 이루어져있는데, 그 안을 뜯어보면 영어 백과사전, 뉴스 기사들, 문학 작품, 웹에 있는 자료들 등.. 굉장히 다양한 출처로부터 가져왔다.
그럼 여기서 두 가지의 의문이 생길 수 있는데,
1. 최신의 large pretrained models 가 광범위하게 작동하는지
2. 특정 도메인에 대한 별개의 pretrained model을 만드는게 도움이 되는지
이전 연구들을 살펴보면, 이 의문과 관련하여 특정 도메인의 라벨링되지 않은 데이터에 대해
continued pretraining하는 것에 대한 이점을 증명하려는 시도가 있었다.
하지만 이 시도들은 두 가지의 한계가 있었는데,
1. 한 번에 하나의 도메인에 대해서만 고려하고, 가장 최근 언어모델들보다는 더 작고 덜 다양한 코퍼스에 사전학습된 언어모델(BERT와 같은 모델이 아닌)을 사용하였다는 점
2. continued pretraining의 장점이 사용가능한 라벨링된 task 데이터의 양과 같은 요소나 오리지날 도메인과 타겟 도메인과의 거리와 같은 요소에 따라 어떻게 다른지에 대해서도 알려지지 않았다는 점
따라서 본 논문의 contribution은 다음과 같다.
① A thorough analysis of domain- and task-adaptive pretraining across 4 domains and 8 tasks, spanning low- and high-resource settings
② An investigation into the transferability of adapted LMs across domains and tasks
③ A study highlighting the importance of pretraining on human-curated datasets, and a simple data selection strategy to automatically approach this performance
요약하자면,
① 4개의 도메인과 8개의 tasks에 DAPT와 TAPT에 대한 철저한 분석
② Adapted 언어모델의 transferability에 대한 조사
③ 인간이 직접 curated한 데이터셋에 대해 사전학습하는 것에 대한 강조, 그리고 성능를 위한 간단한 데이터 선택 전략
2. Background
BERT의 pretraining과 finetuning 과정에 대해 알아보자.

1. 몇백만개의 파라미터를 가진 Neural Language Model(LM)이 큰 unlabeled data에서 학습된다.
2. 사전 학습된 모델을 통한 Word representations은 fine-tuning등의 과정과 함께 downstream task을 위한 supervised training에서 재사용된다.
이러한 사전학습된 언어모델의 한 예가 RoBERTA이다.
RoBERTA가 BERT보다 더 좋은 성능을 보여줬기 때문에 이 논문은 RoBERTA를 baseline 모델로 선택하였다.
하지만 앞서 잠깐 언급했듯이, RoBERTA의 사전학습 말뭉치가 많은 곳에서부터 왔음에도 불구하고
많은 영역을 커버할 수 있을만큼 충분히 다양한지에 대해서는 확실하지 않다.
따라서 이 논문의 저자들은 RoBERTA의 도메인 외의 것들을 이해하고자 한다.
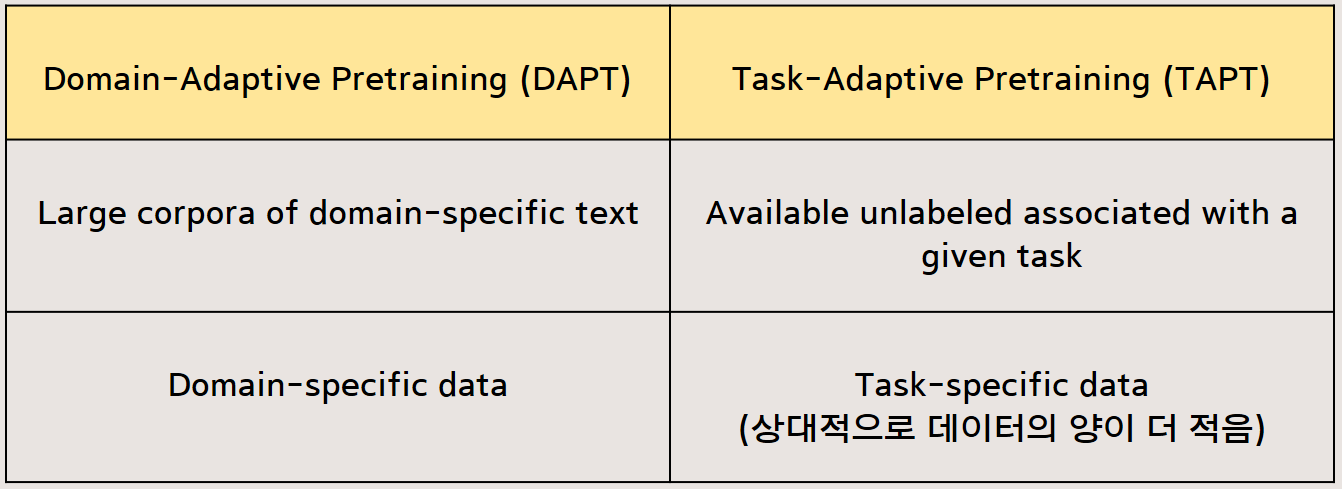
이를 위해서, RoBERTA를 두 가지 카테고리의 unlabeled data를 이용한 continued pretraining을 해서 adaptation하였다.
첫번째 카테고리는 domain-specific text의 큰 말뭉치를 이용한 DAPT이고,
두번째는 주어진 task와 관련된 unlabeled data를 이용한 TAPT이다.
3. Experiment: Domain-Adaptive Pretraining
BioMed, CS, News, Reviews 4개의 도메인 선정하여 실험을 진행했다.
해당 도메인을 선정한 이유는
① Popular in previous work
② Datasets for text classification are available in each
정리하자면, RoBERTA를 4개의 unlabeled domain-specific text의 큰 말뭉치에서 pre-training하는 것이다.

+Analyzing Domain Similarity
DAPT를 하기전에, 본 논문의 저자들은 우선 RoBERTA의 pretraining 도메인과 target 도메인간의 유사도를 정량화하고자 하였다. 유사도 정량화 과정은 다음과 같다.
우선, 각 도메인에서 가장 빈번한 unigrams 10000개(stopwords 제외)를 포함한 도메인 사전을 만든다.
-REVIEWS 데이터셋의 경우, 데이터들의 길이가 짧기 때문에 150K개의 문서를 사용
-다른 세 개의 도메인의 경우, 50K개의 문서를 사용
-오리지날 사전학습 말뭉치의 경우, 공개되지 않았기 때문에 RoBERTA의 사전학습 말뭉치와 유사한 sources에서 50K개의 문서를 샘플링
*RoBERTA의 pretraining corpus domain과 얼마나 유사한지 확인한 결과는 다음과 같다.

Similar → News, Reviews
Dissimilar →BioMed, CS
RoBERTA의 사전학습 domain이 NEWS와 REVIEWS와 큰 overlap을 보임을 확인할 수 있다.
이 결과로 본 논문의 저자들은 더 도메인이 다를수록, 더 DAPT에 대한 잠재력이 높다고 가정한다.
<Results on Pretraining>
• 각 도메인 별로 RoBERTa-base를 12.5k step씩 학습
• 학습 전후의 Masked Language Model Loss 측정

저자들은 각 도메인에서의 RoBERTA의 masked LM loss을 DAPT 전과 후에서 각각 보여주었다. 여기서 masked LM loss가 DAPT후에 NEWS데이터셋을 제외한 모든 도메인에서 감소함을 알 수 있다.
Biomed, cs에서 제일 많이 감소, review에는 조금 감소, news는 오히려 높음.
따라서, "The more dissimilar the domain, the higher the potential for DAPT" 입증가능하다.
<Results on Downstream Tasks>

BIOMED, CS 그리고 REVIEWS 데이터셋에 대해서는 일관된 성능개선을 확인하면서 target 도메인이 ROBERTA의 source 도메인보다 먼 경우에서의 DAPT의 이점을 확인하였다.
DAPT가 NEWS 도메인의 AGNEWS task에서 더 나은 성능을 보여주지 않았음에도 불구하고, HYPERPARTISAN에서 확인한 이점들은 DAPT가 심지어 ROBERTA의 source 도메인과 더 밀접한 tasks에도 유용한 것을 확인시켜주었다.
그러면 한 가지의 의문이 생길 수 있다.
“더 많은 데이터로 pretrain 하는데 성능이 향상되는 건 당연하지 않아?”
그렇지 않다는 것을 실험을 통해 입증하는데,

ㄱDAPT의 사전학습 과정은 다음과 같다.
First Step: Pretrain with General Domain
Second Step: Additional Pretrain with Unrelated Domain
DAPT가 ㄱDAPT보다 성능이 우수함을 보였고, ㄱDAPT는 RoBERTA보다 낮은 성능을 보여주었다.
ㄱDAPT를 보면, 더 많은 데이터를 사용했음에도 전반적으로 성능이 감소하는 현상이 나타났다.
+Domain Overlap
본 논문에서는 도메인 간의 겹치는 부분을 unigram을 통해서 확인하였다.

unigram의 40%은 REVIEWS와 NEWS가 공유한다.
즉, 도메인간의 경계선들이 "fuzzy“한 부분이 있다는 것을 알 수 있다.
또한 질적으로(qualitatively) 도메인간의 overlapped documents를 확인해보았는데,
왼쪽이 REVIEWS, 오른쪽이 NEWS이다.

NEWS와 REVIEW 데이터가 상당히 겹치는 것을 확인할 수 있다.
RoBERTA를 REVIEWS tasks에 NEWS 데이터에 적용해도 괜찮았다.
DAPT on NEWS achieves (task: review) 결과,
65.5 on HELPFULNESS, 95.0 on IMDB 로 성능이 괜찮았다.
미래 연구 과제로, 예측하지 못한 domain 사이의 유의미한 transfer에 대한 연구를 제시한다.